

Demystifying machine learning through hands-on collaboration with chatGPT: A journey from uncertainty to mastery, exploring RandomForest and LogisticRegression for practical football predictions.
I’ve been dabbling around in machine learning for a while by doing boot camps, and reading articles but truth be told, it never really sunk in how one can create a practical model you understand without just copy-paste and clicking the run button.
I did not do this by myself if I have to be completely honest. I have to thank my coding buddy chatGPT for patiently listening and working with me until I was able to successfully create the prediction model.
To be able to argue with chatGPT until you get to the right place and have the correct implementation is incredible and one achieves a higher learning experience because you and chatGPT have to figure it out together. chatGPT was not able to give me the answer straight away. It took some time and collaboration to come to the correct code.
The Model
I’ve been dabbling around in data science for a while by doing boot camps and reading articles. Truth be told, it never really sunk in how one can create a practical model you understand without just copy-paste and clicking the run button.
I did not do this by myself if I have to be completely honest. I have to thank my coding buddy chatGPT for patiently listening and working with me until I was able to successfully create the prediction model.
Out of curiosity, I’m employing two models to contrast outcomes for increased insight and thoroughness.
Some important components
- International football results from 1872 to 2023 from kaggle.com
- RandomForestClassifier from sklearn.kit
- LogisticRegression from sklearn.kit
LogisticRegression is a statistical method used for binary classification, a type of predictive analysis. It’s particularly well-suited for scenarios where the outcome is dichotomous, meaning there are only two possible classes.
RandomForestClassifier is an ensemble of decision trees, typically using bagging. It creates multiple decision trees and merges them together to get a more accurate and stable prediction.
Bagging, or Bootstrap Aggregating, is an ensemble learning technique used to improve the stability and accuracy of machine learning models by training multiple models on different bootstrap samples (subsets with replacement) of the dataset and then aggregating their predictions, typically through averaging or majority voting. This approach is particularly effective with high-variance models like decision trees, reducing overfitting and leading to more robust and reliable predictions.
I decided to use both these regressions for this example to investigate how it works and what the differences in accuracy and results are. Let’s dive in, shall we?
The Code
The packages we require for this are scikit-learn and Pandas
pip install scikit-learn, pandasAlternatively, add these into a requirements.txt row separated and run the following command
pip install -r requirements.txtI will load the fifa_football_results.csv, which includes 45,000 current football results, into a pandas DataFrame.
df = pd.read_csv("fifa_football_results.csv")Create a target variable representing the match outcome for the home team
df['home_team_result'] = df.apply(lambda row: 'win' if row['home_score'] > row['away_score'] else ('lose' if row['home_score'] < row['away_score'] else 'draw'), axis=1)This is the part where we find the input and output columns and encode them for the models to process. LabelEncoder is a straightforward tool for converting categorical text data into numerical form, making it suitable for use in various machine learning models, especially for encoding target variables.
label_encoder = LabelEncoder()
df['home_team_result_encoded'] = label_encoder.fit_transform(df['home_team_result'])
Next, we select the feature columns. We are using home_team and away_team for input and the home_team_result_encoded as output to predict which home_team is most likely to win.
X = df[['home_team', 'away_team']]
y = df['home_team_result_encoded']This code creates an instance of OneHotEncoder to transform categorical data in X into a binary matrix, representing each category with a unique combination of zeros and ones, and then constructing a new DataFrame X_encoded with these transformed features, each named after its corresponding category.
encoder = OneHotEncoder(sparse=False)
X_encoded = pd.DataFrame(encoder.fit_transform(X), columns=encoder.get_feature_names_out(X.columns))
This code splits the dataset into training and testing subsets: X_train and y_train are the features and labels for training, while X_test and y_test are for testing. It allocates 80% of the data for training and 20% for testing, with a fixed random state for reproducibility.
X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, test_size=0.2, random_state=42)
This code trains two machine learning models, Logistic Regression and Random Forest Classifier, on a training dataset (X_train, y_train). It then uses these models to predict outcomes on a separate test dataset (X_test).
The accuracy and detailed performance metrics of each model’s predictions are computed and displayed, using the actual test labels (y_test). This allows for a comparison of the effectiveness of the Logistic Regression and Random Forest models for the given data.
classifier_log = LogisticRegression(max_iter=100)
classifier_log.fit(X_train, y_train)
classifier_rfc = RandomForestClassifier(n_estimators=50, max_depth=100, n_jobs=-1)
classifier_rfc.fit(X_train, y_train)
y_pred_log = classifier_log.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred_log))
print("LogR Classification Report:\n", classification_report(y_test, y_pred_log))
y_pred_rfc = classifier_rfc.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred_rfc))
print("RFC Classification Report:\n", classification_report(y_test, y_pred_rfc))
These two methods, predict_match_log and predict_match_rfc, are designed to predict the outcome of a match between two teams using Logistic Regression and Random Forest Classifier models, respectively.
Both methods take the names of the home and away teams as input, encode these names using a predefined encoder, and then use their respective trained models (classifier_log for Logistic Regression, classifier_rfc for Random Forest) to predict the match outcome. The predicted results, initially in encoded form, are then transformed back to their original label form using label_encoder, and the final predicted outcome is returned.
def predict_match_log(home_team, away_team):
new_input = pd.DataFrame({'home_team': [home_team], 'away_team': [away_team]})
new_input_encoded = pd.DataFrame(encoder.transform(new_input), columns=encoder.get_feature_names_out(X.columns))
predicted_result_encoded = classifier_log.predict(new_input_encoded)
predicted_result = label_encoder.inverse_transform(predicted_result_encoded)
return predicted_result[0]
def predict_match_rfc(home_team, away_team):
new_input = pd.DataFrame({'home_team': [home_team], 'away_team': [away_team]})
new_input_encoded = pd.DataFrame(encoder.transform(new_input), columns=encoder.get_feature_names_out(X.columns))
predicted_result_encoded = classifier_rfc.predict(new_input_encoded)
predicted_result = label_encoder.inverse_transform(predicted_result_encoded)
return predicted_result[0]We are going to use as input two teams, a home team, and an away team. It does not matter if this is a natural ground for the sake of the exercise the team being entered first is the home team and also the result of the prediction.
home_team_input = input('Enter your home team: ')
away_team_input = input('Enter your away team: ')
predicted_outcome_log = predict_match_log(home_team_input, away_team_input)
predicted_outcome_rfc = predict_match_rfc(home_team_input, away_team_input)
print("Predicted Result for the home team:", predicted_outcome_log)
print("Predicted Result for the home team:", predicted_outcome_rfc)The Result
The whole point of the exercise besides predicting a winner was to understand which model would work best for this data using standard configuration. I don’t have the skill or the computing power to optimize these models.
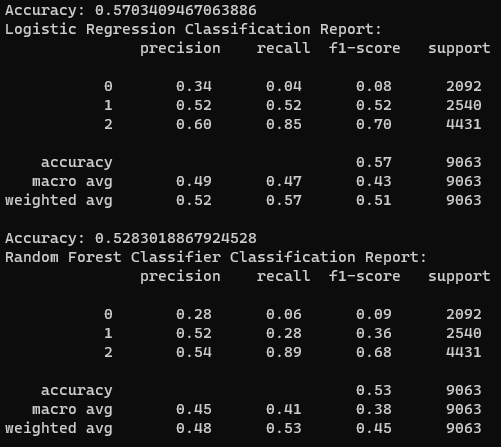
LogisticRegression has a higher accuracy in predicting the winner with 57% compared to the 52% for RandomForestClassifier. The latter would be better for more complex predictions, and that is why the former has a higher accuracy—it is better to work with less complex datasets and predictions.
I’m going to use the following sets of 2 teams to run the model. I’m expecting the first
- England vs Norway
- Argentina vs Brazil
- South Africa vs Wales
In the first matchup, I expect England to win. It is also worth noting that these teams have played against each other in the past. The second matchup I expect to be very close and I cannot predict who will be the winner. This should be the more fun exercise. Lastly, I chose two teams who have never played against each other.
…and the winner is
England vs Norway

Winner: England
Argentina vs Brazil

Winner: Argentina
South Africa vs Wales

Winner: Wales
Conclusion
It was a fun first outing and a completely different experience from doing boot camps like kaggle.com and datacamp.com for example. With no knowledge of these models and machine learning functions I had to start from scratch and with some guidance from chatGPT, I was able to get to the correct starting point which always takes the longest.
With chatGPT solving all our problems, it is still worth understanding the basics of machine learning. That is what I am to do while. Organizations still need to crunch very large datasets for new analytics and insights.
Please find my code repository on Github